Ruitao
Wu
2021 -
2022
- Contributions:
- Traffic Data Collection
- Vechile Labeling
- Algorithm Development
This project is associated with the Real-time Traffic Monitoring Project at ARCS at CSUN. Vehicle detection and classification are important for intelligent transportation planning, directly impacting traffic flow and management efficiency. There are three main approaches for detecting and classifying objects in 3D point cloud data: projection-based, voxel-based, and point-based methods[1]. A recent study examined autonomous driving models and proposed a convolutional neural network (CNN), which was trained and tested on the PandaSet dataset, that showed in average precision ranging from 69.9% to 74.2%, with average recall between 69.2% and 79.7%[2]. In this project, we investigated vehicle detection and classification methods for 3D roadside traffic flow analysis.
We conducted roadside traffic data collection with a 3D Velodyne 32C Lidar sensor camera and a stereo-based depth 2D camera.


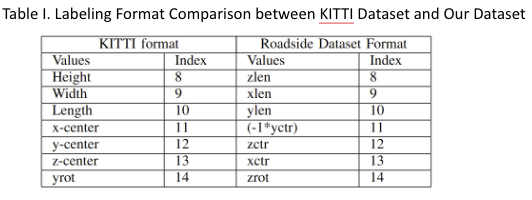
Manual labeling was performed in Matlab for the frames where a vehicle enters and exits the camera frame, and then intervening frames labeled automatically using the auto-labeling Point Cloud Temporal Interpolator. For vehicles turning at intersections or being obscured, otherwise, each frame needs to be manually labeled. We label the traffic dataset using LiDAR Labeler in MATLAB, and then organize them to be the same as the KITTI dataset format.
KITTI is a dataset for autonomous driving developed by the Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago. It is a collection of images and LIDAR data used in computer vision research, such as stereo vision, object detection, and 3D tracking.
Author: Jonathan Cordova
We implemented a Complex-YOLO [3] projection-based model by converting 3D point
cloud data into a 2D bird-eye-view projection and applying the YOLO model
for vehicle detection and classification. Our experimental results demonstrated
that using transfer learning as a training technique and normalization of
the rotation angle enhanced the model performance for vehicle detection and classification.
Data Labeling Formatting: We label the traffic dataset using LiDAR Labeler in MATLAB, and then organize them to be the same as the KITTI dataset format.
Converting PCAP File into BIN Files: Converting a PCAP file into BIN files begins by separating the PCAP file into multiple Point Cloud Data (PCD) files. Afterward, these PCD files are converted to BIN binary format while preserving the data's reflectivity (intensity) attribute.
Complex-YOLO Convolutional Neural Networks Model: The Complex-YOLO framework is configured to recognize three categories: cars, cyclists, and pedestrians. The neural network layers and filter values are modified to expand from three to nine categories to extend its classification capabilities for additional vehicle types.
Transfer Learning: Transfer learning is a technique where a pre-trained model is used to train a new model, allowing it to benefit from the knowledge gained earlier. We apply the transfer learning to our roadside traffic dataset, ensuring that the data format matches that of the pre-trained model.
Pipeline of the Complex-YOLO Algorithm:
Transform LiDAR frames into bird's-eye-view (BEV) images as input for CNN
Efficient Region Proposal Network (E-RPN) identifies potential object regions for the detection and classification of vehicles.
Data is collected at the roadside traffic intersection of Zelzah Avenue and Plummer Street in Northridge, California. Using the LiDAR Labeler in MATLAB, tags for vehicle types ('Sedan', 'Truck', 'Motorcycle', 'SUV', 'Semi', 'Bus', and 'Van') are added. Our roadside dataset was divided into distinct subsets for training and evaluation, with 80% (5,165 frames) for training and 20% (1,292 frames) for evaluation.
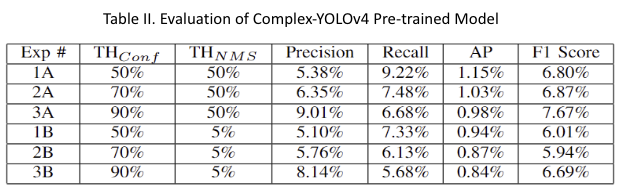
Baseline Model: Table II shows the performance of a pre-trained Complex-YOLOv4 model, originally trained on the autonomous driving KITTI dataset, in evaluating our roadside traffic flow dataset for vehicle type ‘Sedan’.
Transfer Learning Model: Transfer learning (TL) models were developed and trained using knowledge gained from the baseline model. The performance results are shown in Table III. when implementing the transfer learning process without normalizing the vehicle rotation (orientation) angle, the highest precision achieved was 89.71%, with a recall of 85.15% at TF epoch 5. Conversely, the highest recall attained without normalization was 86.04%, with a precision of 86.86% at TF epoch 15.
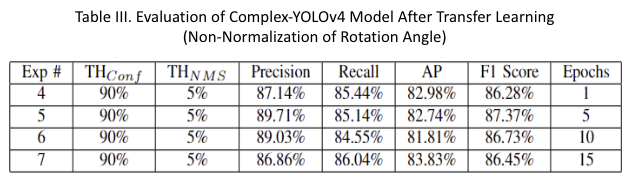
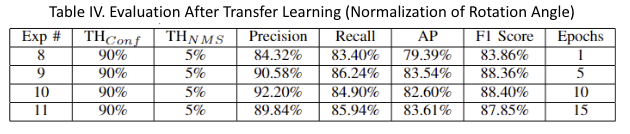
Table IV results show that normalizing the rotational (vehicle orientation) angle of data labels improved model performance significantly. The best precision recorded was 92.20%, with a recall of 84.90% at TF epoch 10. Additionally, the highest recall achieved with normalization was 86.26%, with a precision of 90.58% at TF epoch 5.
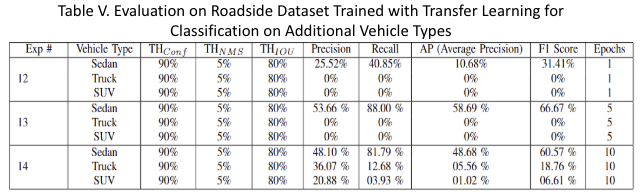
Expanding on Vehicle Type Classification Table V shows better performance was achieved for the 'Sedan' class, as there were more instances of sedans in our roadside traffic dataset. With additional transfer learning epochs, vehicles of 'Truck' and 'SUV' could be classified.
Author: Rachel Gilyard
Improved traffic monitoring, with better roadside vehicle detection and
classification, can help make driving safer. Information on the type and
density of cars can help transportation planners to better design roads
and provide more timely road maintenance. Current 2D RGB vehicle detection
methods don't provide depth information and perform poorly in low visibility
conditions like nighttime. Most open-source 3D LiDAR vehicle classification
models are slow and don't reach the speed needed for real-time systems.
Background filtering is not uncommon in 3D object detection, but there is a
lack of data on its costs and benefits. Using background filtering with the
PointPillars model reduced its computational load and inference time.
The azimuth-height preprocessing algorithm showed an improvement of 6% for
average precision with the dynamic background filter. This method also
achieved a 31% reduction in inference time, including the time to filter
the background LiDAR points. With more accurate predictions and faster
inference, background filtering is a worthwhile technique to pursue when
attempting to use 3D vehicle detection models in real-time systems.
Background Filtering: Two strategies were used for background filtering. The first with a background map holding the maximum distance at a given azimuth and elevation angle, and the second with a similar map that keeps track of the greatest height at a given azimuth-elevation. The filtering step took 6.2ms per frame (124 ms to filter one second of traffic frames).
PointPillars Model Evaluation: MMDetection3D library’s implementation of PointPillars was used for 3D object detection. MMDetection3D’s model comes pre-trained on the KITTI dataset, with a version that detects cars, and a version that detects cars, pedestrians, and cyclists.
Inference Pipeline: The background Map Updater accepted raw packets from the Velodyne VLP 32c sensor and parse them with the Velodyne Decoder package, which is written in Python and C++. The pipeline was written in Python with Numba used for acceleration. The pre-trained model was sourced from the mmdet3d API.
This project is supported by:
(1) Autonomy Research Center for STEAHM (ARCS) at CSUN
(2) SECURE For Student Success (SfS2) Program and funded by the United States Department of Education FY 2023 Title V, Part A, Developing Hispanic-Serving Institutions Program five-year grant, Award Number P31S0230232, CFDA Number 84.031S;
[1] Y. Wu, Y. Wang, S. Zhang, and H. Ogai, “Deep 3d object detection networks using lidar data: A review,” IEEE Sensors Journal, vol. 21, no. 2, pp. 1152–1171, 2021.
[2] S. Zhou, H. Xu, G. Zhang, T. Ma, and Y. Yang, “Leveraging deep convolutional neural networks pre-trained on autonomous driving data for vehicle detection from roadside lidar data,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 11, pp. 22 367–22 377, 2022.
[3] M. Simon, S. Milz, and H.-M. G. Karl Amende, “Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds,” in ECCV Workshops, 2018. [Online]. Available: https://api.semanticscholar.org/CorpusID:53512298
Student teams participated in this project




